Chance News 61
Quotations
If I come in one day and say I think gold is going up and bet on that, it takes nothing away from Wall Street.... It's no different than betting on the Dolphins vs. the Jets.
A sports-betting executive at a Las Vegas casino, quoted in “Whether Bonds or Touchdowns, They’re Still a Gamble”
by Alexandra Berzon, The Wall Street Journal, February 5, 2010
A frequentist would say the chances of love are small, using 1 in a million as an close approximation. But I'd rather let a Bayseian make the call, who would conclude it's certain based on observed information.
From Valentine's Day statistical love poems at Andrew Gelman's blog, February 14 (of course), 2010
Political scientists aren’t going to like this book, because it portrays politics as it is actually lived by the candidates, their staff and the press, which is to say – a messy, sweaty, ugly, arduous competition between flawed human beings – a universe away from numbers and probabilities and theories.
Marc Ambinder, in
“The Juiciest Revelations In ‘Game Change’”, The Atlantic, January 8, 2010
Danish scientist Kaare Christensen and his colleagues have calculated a different kind of projection [assuming that] longevity improvements will continue at their current pace [instead of current death rates remaining constant]. In that model, more than half the children in the developed world will be around for their 100th birthday. Now may be a good time to invest in candles.
Laura Blue, in “Your Kids Could Reach 100”, TIME, February 11, 2010
Forsooth
Census errors
Can you trust Census data?
by Justin Wolfers, New York Times, Freakonomics blog, 2 February 2010
Census Bureau obscured personal data—Too well, some say
by Carl Bialik, Numbers Guy column, Wall Street Journal, 6 February 2010
These stories describe problems with the Census Bureau' IPUMS (Integrated Public Use Mircodata Series) data, which provides subsamples of Census data to outside researchers. In order to protect the privacy of citizens, the records are altered slightly. For example, incomes may be rounded and ages may be tweaked by a small amount. Ideally this would make it impossible to identify any particular individual, while at the same time not introducing any meaningful distortions into the overall demographic profile.
Unfortunately, it appears that serious distortions have resulted. A recent NBER working paper details the problems, which seem to be especially pronounced in data for ages 65 and above. The Freakonomics post reproduces the following graph from the paper
{kind=link}
which shows how total population estimates based on the microdata diverge from the actual Census counts for older Americans. Furthermore, breakdowns within particular age groups are also distorted. For example, The Wall Street Journal article has an interactive graphic, revealing how data released in 2006 showed inexplicable fluctuations from one age year to the next in the percentage of women who were married (those errors were corrected in 2007).
As Bialik notes, "The anomalies highlight how vulnerable research is to potential problems with underlying numbers supplied by other sources, even when the source is the government. And they illustrate how tricky it can be to balance privacy with accuracy."
Submitted by Bill Peterson
Height bias or data dredging?
Soccer referees hate the tall guys
Wall Street Journal, 8 Feburary 2010
According to the article, "Niels van Quaquebeke and Steffen R. Giessner, researchers at Erasmus University in Rotterdam, compiled refereeing data from seven seasons of the German Bundesliga and the UEFA Champions League, as well as three World Cups (123,844 fouls in total)" and found:
| Height Difference | Probability of Foul Against Taller Player |
| 1-5 cm | 52.0% |
| 6-10 cm | 55.4% |
| > 10 cm | 58.8% |
| Avg. Height of Perpetrator | Avg. Height of Victim |
| 182.4 cm | 181.5 cm |
Note that the height difference on average is only 0.9 cm!
Submitted by Paul Alper
Poll question wording affects results
“New Poll Shows Support for Repeal of ‘Don’t Ask, Don’t Tell’”
by Dalia Sussman, The New York Times, February 11, 2010
"Support for Gays in the Military Depends on the Question"
by Kevin Hechtkopf, CBS News, February 11, 2010
These articles describe how the wording of a February 5-10, 2010, NYT/CBS News poll affected the results.
When half of the 1,084 respondents were asked their opinions about permitting “gay men and lesbians” to serve in the military, 70% said that they strongly/somewhat favored it. Of the other half of respondents who were asked about permitting “homosexuals” to serve, only 59% said that they strongly/somewhat favored it. The gap was much wider (79% to 43%) for respondents identifying themselves as Democrats.
For more detailed poll results, see the CBS News website [1].
Discussion
1. The margin of error for each half sample was said to be +/- 4 percentage points. Would you consider the difference between 70% and 59% statistically significant? If not, why? If so, at what level? What about the difference for Democrats?
2. Can you suggest any reason for the difference between 70% and 59% for the half samples? For the difference between 79% and 43% for the Democratic half samples?
3. What implication(s) do these results have, if any, for ballot-question writers?
Submitted by Margaret Cibes based on a suggestion of Jim Greenwood and an ISOSTAT posting by Jeff Witmer
Disability to present accurate statistics
The Odds of a Disability Are Themselves Odd Ron Lieber, The New York Times, February 5, 2010.
What are your chances of needing disability insurance?
You have an 80 percent chance of becoming disabled during your working years. Or maybe it’s 52 percent. Or possibly 30 percent.
Why all the variation? Part of it depends on your definition of disability. One quoted statistic was too high because
the statistic comes from the National Safety Council, which describes “disabling” pretty loosely. “It interferes with normal daily activity one day beyond the day of injury,” said Amy Williams, a spokeswoman for the National Safety Council. “It doesn’t mean they weren’t able to go to work. It may mean that they twisted their ankle and couldn’t go to Pilates that night.”
A good estimate of disability, one that defines disability (an injury that keeps you out of work for 90 days or more) and a provides a time frame for the individual (probability of a disability event between the ages of 25 and 65), appears to be around 30%. But even that number needs to be qualified.
Numbers for white-collar workers are usually lower than for assembly line workers. If you have no chronic conditions, eat decent food and avoid cigarettes, your odds may drop to 10 percent, according to the “Personal Disability Quotient” quiz on the Web site of the Council for Disability Awareness.
And there are even more qualifiers.
Here are a few other things to keep in mind if you’re running your own numbers. Some people lie about being disabled, and their fake claims skew the actuarial data, though no one knows by how much. Lower your odds a bit to account for the cheaters. Lower them some more in recognition of the fact that people who buy their own policies also tend to actually use them.
This is not to imply that disability insurance is a bad deal. The article failed to make this point, but insurance makes sense for covering catastrophic events of whatever probability, that would otherwise bankrupt an individual. It is the magnitude of the potential loss, rather than the probability, that largely determines whether you should buy insurance.
Submitted by Steve Simon
Improving your odds at online dating
Looking for a Date? A Site Suggests You Check the Data. Jenna Wortham, The New York Times, February 12, 2010.
A dating site, OkCupid, decided to help its users by sharing statistics on its blog--statistics on what worked and what didn't.
If you’re a man, don’t smile in your profile picture, and don’t look into the camera. If you’re a woman, skip photos that focus on your physical assets and pick one that shows you vacationing in Brazil or strumming a guitar.
Here are some additional insights.
“If you want worthwhile messages in your in-box, the value of being conversation-worthy, as opposed to merely sexy, cannot be overstated,” wrote Christian Rudder, another OkCupid founder, in the post. Last fall Mr. Rudder looked at the first messages sent by users to would-be mates on the site, and which ones were most likely to get a response. His analysis found that messages with words like “fascinating” and “cool” had a better success rate than those with “beautiful” or “cutie.”
The insights posted on the blog led to a lot of press and a surge of new customers.
Since OkCupid started its blog, the number of active site members has grown by roughly 10 percent, to 1.1 million, according to the company.
Submitted by Steve Simon
Questions
1. Why would the publishing of statistics lead to a surge of new members rather than just changing the behaviors people used on their existing dating site?
2. How could you quantify information about profile pictures that involve inherently subjective judgments?
Children: Just Say No To Sex
“Some Success Seen in Abstinence Program”
by Lindsey Tanner (AP), TIME, February 1, 2010
“Abstinence-Only Classes Reduced Sexual Activity, Study Found”
by Jennifer Thomas, Business Week, February 1, 2010
The National Institute of Mental Health funded a University of Pennsylvania randomized control study of 662 African-American children in 4 Philadelphia public schools. Children were 6th or 7th graders age 10-15 years. Study results were released in the February 2010 edition of Archives of Pediatrics & Adolescent Medicine; see “Abstract”.
An 8-hour abstinence-only intervention targeted reduced sexual intercourse; an 8-hour safer sex–only intervention targeted increased condom use; 8-hour and 12-hour comprehensive interventions targeted sexual intercourse and condom use; and an 8-hour health-promotion control intervention targeted health issues unrelated to sexual behavior. Participants also were randomized to receive or not receive an intervention maintenance program to extend intervention efficacy.[2]
Assignments involved helping the students to “see the drawbacks to sexual activity at their age, including having them list the pros and cons themselves.” Classes met at schools on weekends.
After 2 years, with about 84% of the students still enrolled in the program, almost 50% of the control group reported that they had "ever" had sexual intercourse[3], while only 34% of the abstinence-only group reported the same behavior. Also, 29% of the control group reported having had sexual intercourse in the "previous 3 months during the follow-up period," as opposed to 21% of the abstinence-only students. The study did not collect data on pregnancy or sexually transmitted diseases.
Authors of the study do not recommend abandoning “more comprehensive sex education.” An Archives’ editorial contains the comment:
No public policy should be based on the results of one study, nor should policy makers selectively use scientific literature to formulate a policy that meets preconceived ideologies.
Discussion
1. How many of the students had dropped out of the program at the end of 2 years? Do you think that the study’s results would have been significantly different if these students had not dropped out?
2. Do you think the fact that more than half (54%) of the participants were girls [4] affected the results?
3. Researchers had to have received informed consent from each participant in this study. How might the fact that this consent probably had to come, legally, from parents/guardians have influenced the results of the study?
4. What factors might have influenced individual students in their responses about their sexual activities?
5. What clarification might you want about the time frames of sexual intercourse among the students, with respect to "ever" having had it or having had it "during the previous 3 months during the follow-up period"? Why might you want to know how many of these students had had sexual intercourse prior to the classes?
6. What additional information about each of the four subgroups and/or the "intervention maintenance program" might help a public-policy maker form his/her decisions with respect to sex education for school children? Assume, contrary to what we know, that adverse public attitudes toward sex education are not a factor in these decisions.
7. Based on their sample results, the researchers estimated, with 95% confidence, that the probability of abstinence-only education reducing “sexual initiation” in the general population (population undefined) lies in the interval (0.48, 0.96)[5]. If the probability actually does lie in that interval, what does that mean about the “treatment,” in non-statistical terms? Can you draw any conclusion as to whether abstinence-only education would be more likely to be effective or not?
Submitted by Margaret Cibes
Fractions of a penny may count
“For Some Firms, a Case of ‘Quadrophobia’”
by Scott Thurm, The Wall Street Journal, February 14, 2010
Two Stanford researchers have examined nearly half a million earnings reports over a 27-year period and found evidence that “many companies tweak quarterly earnings to meet investor expectations, and the companies that adjust most often are more likely to restate earnings or be charged with accounting violations.” Their working paper, “Quadrophobia: Strategic Rounding of EPS Data,” can be downloaded from a website [6].
They analyzed standard earnings-per-share ratios down to a tenth of a cent and noticed that some companies had “nudged” these figures upward by a tenth of a cent or two, which had the effect of producing final figures that were a full cent higher than they would otherwise have been. Apparently even a one-cent increase in expected earnings is significant to investors. This rounding is said to be legal.
When they ran the earnings-per-share numbers down to a 10th of a cent, they found that the number "4" appeared less often in the 10ths place than any other digit, and significantly less often than would be expected by chance. They dub the effect "quadrophobia."
The article provides a chart[7] showing the frequency of digits in the tenth-of-a-cent place for the companies for the period 1980-2006. For the digits 0 through 9, the frequencies range from approximately 8.5 to 10.8 percent (eyeballing).
But the overall effect is striking. In theory, each digit should appear in the 10ths place 10% of the time. After reviewing nearly 489,000 quarterly results for 22,000 companies from 1980 to 2006, however, the authors found that "4" appeared in the 10ths place only 8.5% of the time. Both "2" [about 9.2%] and "3" [about 8.8%] also are underrepresented in the 10ths place; all othe digits show up more frequently than expected by chance.
Companies that are less likely to report 4s in the tenths’ place are those whose earnings-per-share ratios are close to expectations or high. But they are also companies that “later restate earnings or are charged with accounting violations.”
One blogger[8] commented:
I was nailed once by an instructor in high school in an electronics lab in which you are supposed to do an experiment and measure the results, and then be taught the theory and math. I already knew the theory and math, so I just filled out the table. He immediately handed it back to me and said "go do the measurements, even though I know you know this stuff already". I asked, "how did you know?", and he said, our (old analog) meters don't read to two decimal places, unless your eyes are a lot better than mine!
Two other bloggers[9] interacted:
(a) It's not true that 4 should appear as often as every other number. The researchers should refer to Benford's law to determine the expected frequency of the number 4 before making such a claim. This law from number theory has been accepted by courts and successfully used in fraud convictions. And it DOES NOT state that the frequency of all digits should be the same.
(b) Uh -- Benford's law applies to the _first_ digit in a table or list of numbers. These guys were looking at the _last_ digit in a lot of numbers. Please read more carefully next time.
Submitted by Margaret Cibes
Predicting medal counts
Canada vs. the United States: Who wins?
by Daniel Gross, Slate, 12 February 2010
The article is subtitled "An economist predicts the medal counts for the Vancouver Olympics." The economist here is Daniel Johnson of Colorado College. He has developed a model which predicts medal counts for countries from their population, per capita income, climate, political structure and host-nation status. You can read his latest predictions in a press release from the College, which is subtitled "Economics professor’s formula ignores athletes’ skills, yet proves remarkably accurate." Indeed, Johnson's web site here notes that
Beijing 2008 Summer Games had a 0.93 correlation with our predicted results
Torino 2006 Winter Games had a 0.93 correlation with our predicted results
His record at the 2008 Beijing games was reported in a Wall Street Journal article that summer, entitled Want to Predict Olympic Champs? Look at GDP.
Johnson's bottom line for Vancouver was that Canada would win the most medals, with 27 total, just ahead of the US and Norway with 26. So far, however, the Canada has not been as successful as many anticipated--including the Canadians themselves, who had adopted the motto "Own the Podium." Nate Silver has been regularly updating medal projections at FiveThirtyEight.com. His 22 February post, which comes the day after the US hockey team's upset victory over Canada, is entitled Canada Not Owning the Podium. The New York Times has a data map of the current medal count. There is also data from past Olympics, and the historical progression can be viewed in a Gapminder-style animation.
DISCUSSION QUESTION
The Slate article concludes by saying, "In a couple of weeks, we'll check back with professor Johnson and see how his model performed this year." If Canada continues to lag, what explanations do you think he might offer?
Update
With the Games now concluded, we can report the top medal winners in Vancouver were US (37), Germany (30), Canada (26), Norway (23). Shown below is a scatterplot of 2010 total medals vs. 2006 total medals, for all countries that won at least one medal in either year. The correlation coefficient is 0.916. By this measure, we would have done well simply predicting that the Vancouver totals would match the Torino totals, despite some of the surprises this winter.

DISCUSSION QUESTION
This picture is consistent with Johnson's conclusion that "There is a measurable, continuing advantage to certain nations in the Olympic Games." But is the correlation coefficient r an adequate summary for the plot? What does this say about the limitations of r as a measure of accuracy for medal predictions?
Submitted by Bill Peterson
Meaning of mean
“Misleading Indicator”
by Megan McArdle, The Atlantic, November 2009
“Letters to the Editor – Misleading Math?”
The Atlantic, March 2010
This article focuses on the GDP as part of a stream of economic statistics that the TV-viewing public “constantly” receives from the media – “almost all of them bad.” According to McCardle, the GDP has become the nation's “common denominator of economic well-being.”
McArdle lists three ways of building a “well-being” index, all of which have problems.
You can use … “shadow prices,” imputing dollar values to the various things that contribute to our quality of life. But the index usually ends up being incredibly sensitive to your starting assumptions. As [one] economist … says, “How much is a fish worth? .00000000000001 cents per fish or .0000000000000000000000000001 cents per fish? It makes a big difference!” …. The second approach is to attach weights to various indicators and use them to build a composite gauge like the Human Development Index[10]. Unfortunately, the weights will always be somewhat arbitrary [and thus subjectively biased]. …. When all else fails, of course, you can just ask people: Are you better off now than you were three years ago? Even this approach poses problems. …. Surveys ... show that heterosexual men on average have many more sexual partners than heterosexual women do, which is mathematically impossible.
For information about problems with the third approach, see “Chance News 59: Measuring Happiness”.
Meanwhile, two subsequent letter-to-the-editor writers took issue with McArdle’s sentence about sexual partners. Here is one response[11]:
Mathematically impossible? Ten couples in a room. Nine women are monogamous; one has four partners and her spouse. So 90 percent of the women are monogamous, but only 60 percent of the men are. Men lie, but it is mathematically possible.
McArdle replied:
We are talking about two different meanings of the word average. True, in [the given] scenario, it is more common for women to be monogamous than men. But I was using average to describe the mean number of sexual partners, which is to say, the sum of everyone’s number of partners, divided by the number of people. If there are 10 men and 10 women, and one of the women has slept with all 10 men, while the other women are monogamous, the average number of sexual partners is the same for the men and the women. Nine of the men have had two sexual partners, while one of the men has had one partner, for an average of 19/10=1.9. Meanwhile, one of the women has had 10 sexual partners, while the other nine women have had one partner, for an average of 19/10=1.9. The numbers come out the same, no matter how you vary the particulars. Yet surveys can generate differences of three- or fourfold between the mean numbers of sexual partners that women and men report.
Discussion
1. Refer to the letter-to-the-editor’s comments. What was the (arithmetic) mean number of partners for each gender?
2. Which statistic do you think better describes the heterosexual men and women in a population – the percent monogamous or the average number of partners? What considerations might affect your preference?
3. Can you explain how surveys can generate reports of such large differences?
Submitted by Margaret Cibes
(Note: The sex partner conundrum also figured in some news stories back in 2007. See Chance News 29: The Myth, the Math, the Sex.)
Politics, personality, and the brain
"Our Politics May Be All in Our Head"
by Nicholas D. Kristof, The New York Times, February 13, 2010
In this Op-Ed piece Kristof discusses recent research on the relationships among political leanings, emotions, and personality development. The first part of the article focuses on brain research led by Kevin B. Smith of the University of Nebraska-Lincoln that studied the association between political identification and levels of alertness, as detected through the "startle blink" reflex. Kristof writes that the subjects in the study who held traditionally conservative positions-- support of gun rights and warrantless searches, for example-- had a more pronounced startle reflex.
Similar results were obtained when subjects were shown disturbing or disgusting images (such as a person eating a mouthful of worms) and their level of increased skin moisture was recorded--another way to measure the stress response. Participants with more liberal views "released only slightly more moisture in reaction to disgusting images than photos of fruit," while the conservative response "went into overdrive." (Results of this study are in the paper "The Ick Factor: Physiological Sensitivity to Disgust as a Predictor of Political Attitudes".)
The second part of the Op-Ed refers to findings from the book "Authoritarianism and Polarization in American Politics," by Marc J. Hetherington of Vanderbilt University and Jonathan D. Weiler of the University of North Carolina at Chapel Hill. In the book the authors examine, at the state level, the relationship between acceptance of spanking and other corporal punishment and support for either Bush in the 2004 Presidential election. They have also done a similar analysis for the 2008 election--see the graph, below. In addition, the authors discuss their work here.
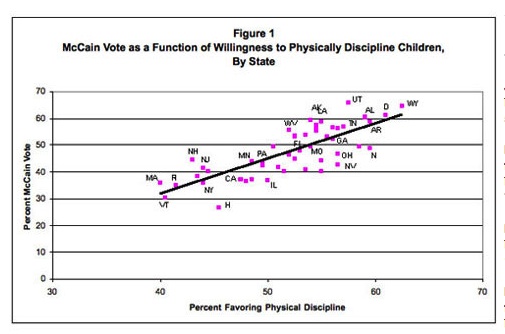{kind=link}
Submitted by Jeanne Albert
An interesting graphic
Not your parents' unaffiliated
New York Times, 20 February, 2010
This graphic accompanies 19 February article, Spirit Quest, in which Charles Blow discussed the results of a Pew Research Center poll entitled Religion Among the Millennials. Americans in the so-called millennial generation, those born in 1981 or later, were more likely than older generations to be unaffiliated with a traditional religion. Nevertheless, they professed a range of spiritual beliefs, which were the focus of Blow's commentary. Here is a portion of the Times graphic.

...

DISCUSSION QUESTION
How effective do you find these graphs for comparing percentages?
Submitted by Paul Alper
Hockey stick?
Tax & Fiscal Policy Task Force Report
Vermont Business Roundtable, January 2010
One of the conclusions of the report (pdf here) is that "Vermont's current fiscal policy is unsustainable and future years look worse" (emphasis added). Unfunded liabilities were identified out as a Key Problem facing the state; the accompanying graph is below.

Check the time scale on those future years!
Suggested by Priscilla Bremser
Danes most satisfied
“Why Danes are smug: comparative study of life satisfaction in the European Union”
by Kaare Christensen, Anne Maria Herskind James W Vaupel, BMJ, 2006
Readers may enjoy this humorous report, and take it et gran salt, or cum grano salis, as they prefer.
These Danish researchers were motivated by two actual publications: the University of Leicester’s The First Published Map of World Happiness [12], and, more significantly, a time series chart of the “Proportion who report to be very satisfied in 15 EU countries according to Eurobarometers”[13].
They started with a number of hypotheses about why Denmark has consistently ranked #1 in “satisfaction” for over 30 years, in general among European Union countries and in particular with respect to Sweden and Finland.
They initially identified and examined 12 potential factors, including hair color (blondes may have more fun), cuisine (despite Danish cuisine as an oxymoron), and alcohol consumption (high consumption may have affected survey results).
Their conclusion describes what they believe are two explanatory factors: the Danish football triumph of 1992 and the Danes’ “consistently low (and indubitably realistic) expectations.”
Year after year they are pleasantly surprised to find that not everything is getting more rotten in the state of Denmark.
Submitted by Margaret Cibes