Chance News 31
Quotation
Statistics are no substitute for judgment.
Henry Clay
Forsooth
The following Forsooth from the Nov. 2007 issue of RSS NEWS.
The odds of an $18 million Lotto win are one in 30 million but in the tiny Northland town of Kaeo they've been slashed to just one in 500. The town is abuzz with gossip that it could be home to New Zealand's biggest ever Lotto winner but Far North district councillor Sue Shepherd says the 500 residents are keeping their cards, and their tickets, close to their chest.
The Dominion Post, New Zealand
22 May 2006
Note: This article is available from Lexis Nexis. Later in the article it is stated that there was a single winner and the ticket was bought at Patel's Price Cutter in Kaeo but not yet claimed. (It was claimed later by a couple who do not live in Kaeo). So why is this a Forsooth? Laurie Snell
Of Italy's 151 Series A players, 52 are non-white, with Inter fielding, 19,
Juventus 12, AC Milan 13, AS Roma 12 and Udinese 10. Messina has eight.The Times
30 November 2005
Using Statistics to bust myths
The MythBusters Answer Your Questions Stephen J. Dubner, Freakonomics Blog, October 25, 2007.
"The MythBusters" is a television show on The Discovery Channel where Jamie Hyneman and Adam Savage examine commonly held myths and see if they have any validity. Their prior experience was in movie special effects and stunts, and sometimes their experiments lead to big (but carefully controlled) explosions. They were interviewed on the Freakonomics blog, and there were a pair of the questions asking why they didn't use more Statistics in their investigations.
"Q: Often, when testing a myth, you conduct one full scale test and then draw your conclusions. I know you are both aware of the scientific method and the need to run multiple trials to fully prove or disprove a theory. How confident are you that when you’ve run one test on a myth, you can then accurately capture whether or not it is true?"
and
"Q: How much statistics training do you guys have, and how much statistics do you use off camera? I get frustrated with the show over what appears to be a lack of statistical knowledge and rigor. (I’m thinking of the “football kick with helium” episode in particular, but the issue is sort of endemic to the show.) I realize that statistics makes for bad TV, while building machines that shoot things and break things make good TV. So the Freakonomics-y question would be: how much of this type of stuff is hidden off-camera?"
Both Jamie and Adam point out their time and budget limitations and remind us that the show has to be entertaining as well as illustrate a scientific approach to investigation. Adam does admit that he'd like to include more statistics, though.
ADAM: These two (very difficult), questions are similar, so I’ll answer them together. I would love to get more statistics into the show, and I’ve been talking to a statistician friend about just that. It’s true that statistics are not very telegenic, and are often difficult to get across.
We do worry about consistency, and it’s usually because our data sets are so small. With larger sets, we can work with things like standard deviation; but with a data set of 2, we don’t have that luxury.
Also, I sense a frustration in some of these questions. I’ll say this: I don’t pretend to be a scientist. We’re not deliverers of scientific truth. But I am curious. And if there’s one complaint I have about people, it’s that most of them aren’t curious enough to look around and figure stuff out for themselves. So if you’re yelling at me at the TV, you’re involved, and as such, I’ve done my job.
Questions
1. Is it true that statistics are not very telegenic? Are there any aspects of Statistics that would lend themselves to a medium like television?
2. The Discovery Channel website has an episode guide. Select a show and explain how statistics could be used to investigate the myth(s) on that episode.
Submitted by Steve Simon
Migration statistics
Stats office to improve data on migration flows, Reuters, 30th Oct 2007.
Smith apologises for foreign workers error, Guardian Unlimited, 30th October 2007.
Undercounted and over here, The Economist, 1st Nov 2007.
How many people live in Britain? We haven't the foggiest idea, The Guardian, 3rd November 2007.
UK politicians were recenly forced to answer the question how many foreign workers were in the country? but were unable to do so. The initial estimate (800,000) had to be revised upwards, not once, but twice (1.1 million, then the government's chief statistician said it was more like 1.5m), much to the government's embarrassment.
The shadow pensions secretary, Chris Grayling, said
This situation just gets worse. It's clear we simply can't trust the figures or statements put out by the Government on migrant workers in the UK. Ministers need to carry out an urgent review of how they handle this data and need to clear up once and for all how many people come to work in Britain.
Then just a few hours after the government was forced to admit it had hugely underestimated the number of immigrant workers, the (UK's) national statistics office (ONS) announced changes to the way it collects migration data. Publishing an interim report into the issue, the ONS said it would increase the sample sizes for its International Passenger Survey and consider making better use of administrative data, such as school and patient registers. The (UK's) International Passenger Survey currently samples around 0.3 percent of people entering and leaving the country at 16 airports, 21 ferry routes and the Channel Tunnel. The ONS said extra "filter shifts" would be introduced at specific airports from next April to reflect the higher number of migrants who arrived and departed from these airports in 2006.
How does the survey work? According to Michael Blastland writing in the Evening Standard
For ferry passengers, a team in blue blazers stands at the top of each of stairs into the passenger deck and scribbles a quick description of every 10th [passenger] aboard. As the ship sails, the blazers go hunting for their sample, the woman in the green hat, the trucker in overalls by the slot machine, and ask them if they plan to stay, then extrapolate.
One objective of this survey is to say how many of the 2.17m jobs created since 1997 have been filled by foreign nationals, the statistic that caused the furore.
Richard Alldritt, the Statistics Commission's chief executive, wants the government to spend more money on improved monitoring of travel movements: the international passenger survey has become a key estimate of migration levels, but Alldritt said it didn't cover every port and that there was
no guarantee that those surveyed give accurate answers and the results have to be scaled up enormously.
The lack of reliable data on migrant flows has been a major headache for policymakers, complicating everything from the allocation of government resources to the setting of interest rates.
US-born, National Statistician Karen Dunnell said
The ONS is engaged in a major programme to improve further the quality of its migration statistics. The International Passenger Survey is a vital source of data on this, so improving the sampling of migrants is a step forward in this very important area of our work.
This week on BBC's Question Time, David Dimbleby asked the audience if they would believe any statistic mentioned by a politician and the audience roared 'No!'.
Questions
- Speculate on what questions might be asked in such a survey?
- What criteria might the ONS use to decide which airports to locate their extra 'filter shifts' at?
- The revised figure of 1.5m included children. What is the implication of counting them as 'workers'?
- Sir Andrew Green, chairman of Migration Watch, which campaigns against mass immigration, claimed that the rise was equivalent to a city the size of Coventry. Is it fair and unbiased to compare the size of the error in the initial estimate to a specific city? Can you think of alternative analogies?
Further reading
- The International Passenger Survey is a survey of a random sample of passengers entering and leaving the UK by air, sea or the Channel Tunnel.
- Over a quarter of million face-to-face interviews are carried out each year with passengers entering and leaving the UK through the main airports, seaports and the Channel Tunnel.
- There are six versions of the questionnaire depending on the mode of transport (air, sea or Eurostar) and which direction the passenger is travelling in (arrivals or departures).
- The sampling procedures for air, sea and tunnel passengers are slightly different but the underlying principle for each is similar. In the absence of a readily available sampling frame, time shifts or crossings are sampled at the first stage. During these shifts or crossings, the travellers are counted as they pass a particular point (for example, after passing through passport control) then travellers are systematically chosen at fixed intervals from a random start.
- Interviewing is carried out throughout the year and over a quarter of a million face-to-face interviews are conducted each year, and represents about 1 in every 500 passengers.
- The interview usually take 3-5 minutes and contains questions about passengers’ country of residence (for overseas residents) or country of visit (for UK residents), the reason for their visit, and details of their expenditure and fares.
- There are additional questions for passengers migrating to or from the UK.
- While much of the content of the interview remains the same from one year to the next, new questions are sometimes added or appear periodically on the survey.
- This issue has been covered in the BBC radio 4 series More or Less.
Submitted by John Gavin.
The Unbreakable Wikipedia?
Creating, Destroying, and Restoring Value in Wikipedia Department of Computer Science and Engineering at the University of Minnesota, 2007.
Univ. of Minnesota: Less Than 1/2 Percent of Wikipedia Content is Damaged Fox News (Twin Cities), November 5, 2007.
The University of Minnesota computer science and engineering faculty and students found that only a few edits inflict damage on the integrity of content within Wikipedia and that damage is typically fixed quickly. The study estimated a probability of less than one-half percent (0.0037) that the typical viewing of a Wikipedia article would find it in a damaged state. However, the problem is clearly growing:
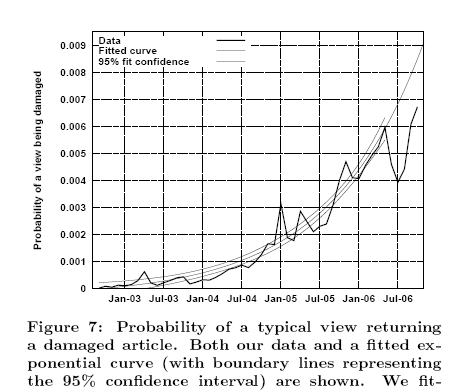{kind=link}
It is important to ask incisive questions about this study, especially to demand a definition of what constitutes "vandalism" and "damage". The following passage from Wikipedia is downright horrid, but would it constitute a "damaged" piece of content? Our assessment is that the Minnesota study would have accepted a passage like this as completely "undamaged".
From the "History of western Eurasia" article in Wikipedia:
As the Viking raids subsided the Magyars arrived. Crossing the Carpathians they, in 896, occupied the Upper Tisza river, from which they conducted raids through much of Western Europe. However, in 955 they were defeated by Otto of Germany at the Battle of Lechfeld. The defeat was so crushing that the Magyars decided that 'if you can't beat them join them' and in 1000 their King was accepting his royal regalia from the Pope. Otto on the strength of that victory was able to secure the tittle of Emperor. This German based Holy Roman Empire was to be the major power in Christian Europe for some time to come. As well as this "rebirth" of Western Roman Empire, the Eastern Roman Empire continued to be the up.
Potential bias in the study
1. From the study:
We assume that one serving of an article by a Wikipedia server is a reasonable proxy for one view of that article by a user.
- Critique:
Humans don't read the entire article every time they load one in their browser. Studies have shown that readers of web pages tend to focus most of their priority on the top-left portion of the page. Therefore, this study is giving equal weight to words that appear at the bottom of an article, even though there is disproportionate reader emphasis on the first paragraph or two of any Wikipedia article.
- Gaming the system:
An editor who wished to maximize his "Persistent word views" legacy would be wise to bury his content in the middle or toward the end of Wikipedia articles, though fewer people being served the article would actually read his content.
2. From the study:
A tempting proxy for article views is article edits. However, we found essentially no correlation between views and edits in the request logs.
- Critique:
Why was there "essentially no correlation"? Popular, often-viewed pages on Wikipedia (examples include the articles about wiki, Chris Benoit, Ann Coulter, List of sex positions, and Jeff Hardy) are frequently semi-protected (only registered users with 4 days of experience may modify the article) or fully-protected (only administrators may access the edit feature). In fact, the above articles have all appeared in Wikipedia's "10 most popular articles of the month" list, and all remain protected from free editing. Therefore, a very powerful inverse relationship between views and edits would exist for Wikipedia's most popular pages; which probably topples the otherwise intuitive correlation between article views and article edits. Are the study's authors cognizant of this?
- Gaming the system:
An editor who wished to maximize his "Persistent word views" legacy would be wise to add his content to contentious, popular articles, just before they are "locked down" from further editing. A Wikipedia administrator would have the capacity to make substantial edits to an article just before himself locking down (or asking an admin colleague to lock down) the very same article.
3. From the study:
...if a contribution is viewed many times without being changed or deleted, it is likely to be
avaluable.
- Critique:
Or, equally likely, the contribution is not being read critically, or even read at all.
- Gaming the system:
An editor who wished to maximize his "Persistent word views" legacy would be wise to add content that is wordy, boring, and dense. Prose that intimidates or sedates the reader would be so bland as to encourage skimming (rather than editing!), every time it is viewed.
4. From the study:
Our software does not track persistent words if text is "cut-and-pasted" from one article to another. If an editor moves a block of text from one article to another, PWVs after the move will be credited to the moving editor, not to the original editors.
- Critique:
Large credit goes, then, to "text movers" rather than "text creators". People who move a lot of text around will typically be busy-body administrators, rather than the careful scholars who painstakingly wrote the material in the first place. It is a known fact that the busiest administrators do a lot of "tidying" of major articles which lack any trace of their own content.
- Gaming the system:
An editor who wished to maximize his "Persistent word views" legacy would be wise to become an administrator, then move a bunch of well-written content from article to article, which is frequently done among articles like "History of Tuscany" to "History of Italy" to "History of the Mediterranean" to "History of Europe" to the God-awful "History of western Eurasia".
5. From the study:
We exclude anonymous editors from some analyses, because IPs are not stable: multiple edits by the same human might be recorded under different IPs, and multiple humans can share an IP.
- Critique:
The same could be said for registered user accounts, which can be used from different IP addresses, by different people who know the password. It is a fact that some contributors to this very Chance News wiki are known to share registered Wikipedia user accounts. Regardless, the study itself found that anonymous IPs made 9 trillion edits out of a total of 34 trillion. Why would the study therefore exclude over 26% of the sample? This would have the effect of elevating the relative strength of contributions by a finite number of registered accounts, which is exactly what the study concludes.
- Gaming the system:
An editor who wished to maximize his "Persistent word views" legacy would be wise to set up an account that he then shares with other like-minded individuals, so that more round-the-clock editing is possible, thereby building credibility in the community as a "dedicated Wikipedian".
6. From the study:
Reverts take two forms: identity revert, where the post-revert revision is identical to a previous version, and effective revert, where the effects of prior edits are removed (perhaps only partially), but the new text is not identical to any prior revision. ...In this paper, we consider only identity reverts.
- Critique:
Identity reverts, since they are a "button" tool that may seem intimidating to an average user, are probably more likely to be used by administrators, not scholars. Therefore, this study again gives extra strength to the actions of mop-wielding admins, rather than earnest shapers of Wikipedia.
- Gaming the system:
To count for more in this study, you wouldn't ever want to work to "improve" fixable recent content in Wikipedia. Rather, revert it, then re-write it in your own words.
7. From the study:
We believe it is reasonable to assume that essentially all damage is repaired within 15 revisions.
- Critique:
This may be so, but Figure 8 in the report also shows that 20% of the "Damaged-Loose" content incidents in Wikipedia are viewed by at least 30 people before they get fixed. Ten percent of such mistakes are viewed by well over 100 people before repaired.
- Gaming the system:
Learning to write mistaken or vandalistic prose in such a way that many, many people read it without "noticing" that it is wrong would be a way to further extend the time and views until detection. The libelous content written about John Seigenthaler, Sr. and about Fuzzy Zoeller went unnoticed for a number of weeks or months without causing any alarm. An effective way to make unsuspecting readers believe a lie in Wikipedia is to show a reference citation next to the false content. The reference need not even link to a source making the same claim you are making.
Rudy wrong on cancer survival chances
The Washington Post Fact Checker, Oct. 30, 2007
Michael Dobbs
This Blog describes its goal as follows:
Our goal is to shed as much light as possible on controversial claims and counter-claims involving important national issues and the records of the various presidential candidates.
Here they discuss Giuliani’s New Hampshire radio advertisement, October 29, 2007.
I had prostate cancer, five, six years ago. My chances of surviving prostate cancer and thank God I was cured of it, in the United States, 82 percent. My chances of surviving prostate cancer in England, only 44 percent under socialized medicine.
It is not clear what is being compared here. It is probably meant to be the survival rate. This is defined by the National Cancer Institution as:
The percentage of people in a study or treatment group who are alive for a given period of time after diagnosis. This is commonly expressed as 5-year survival.
The Giuliani campaign reports that these percentages came from an article in City Journal, a publication of the Manhattan Institute, a conservative research organization. This article, The Ugly Truth About Canadian Health Care, was written by Dr. Lavid Gratzer, a senior fellow at the Manhattan Institute and an adviser for the Giuliani campaign. While the article did not say where the numbers came from, Dr. Gratzer has now explained that they came from a Commonwealth Fund article Multination Comparisons of Health Systems Data, 2000 by Gerard F. Anderson and Peter S. Hussey of Johns Hopkins University. Specifically they came from this graphic in the Commenwealth Fund article:
{kind=link}
The Commonweath Fund provided a a Statement in repsonse to Giuliani’s advertisement. They say:
The incidence rates simply report the number of men diagnosed with prostate cancer in a given year. Prostate cancer mortality rates report the number of men who died of the disease in a given year. Neither speaks to length of survival, and that figure can not be calculated using the others.
But Dr. Gratzer defends Guiliani's ad in an article "On cancer survival rates, Rudy’s right and his critics are wrong" City Journal, 31 October 2007. Here we read:
Let me be very clear about why the Giuliani campaign is correct: the percentage of people diagnosed with prostate cancer who die from it is much higher in Britain than in the United States. The Organization for Economic Co-operation and Development reports on both the incidence of prostate cancer in member nations and the number of resultant deaths. According to OECD data published in 2000, 49 Britons per 100,000 were diagnosed with prostate cancer, and 28 per 100,000 died of it. This means that 57 percent of Britons diagnosed with prostate cancer died of it; and, consequently, that just 43 percent survived.
Finally, from the Washington Post Blog we read:
UPDATE: Maria Comella, deputy communications manager for the Giuliani campaign, sent us the following e-mail explaining the mayor's mistake without quite acknowledging it:
Mayor Giuliani is an avid reader of City Journal and found the passage in the Gratzer article himself. He cited the statistics at a campaign stop, and the campaign used a recording from that appearance in the radio ad. The citation is an article in a highy respected intellectual journal written by an expert at a highly respected think tank which the mayor read because he is an intellectually engaged human being.
Discussion
(1) Do you agree with the Commonwealth Fund statement?
(2) Do you agree with Gretzer's explanation?
(3) Others say that the difference is caused by the fact that the United States screens for Prostate Cancer earlier than England does so of course the survival rate will be longer. Is this relevant to this controversy?
More or less
Lunch with the FT: Andrew Dilnot, by Tim Harford, The Financial Times, 16 Nov 2007.
Chance readers may be interested in a BBC Radio 4 series called More or less, which is about numbers in the news. (The original presenter Andrew Dilnot recently stepped down to be replaced by Tim Hartford, who writes the 'Dear Economist' column for the Financial Times.)
The website for the programme gives a hint at the topics covered:
- predicting bird flu
- measuring happiness
- migrant figures that do not add up (covered in a Chance news article in this issue)
- The dangers of spotting patterns in random things
Dilnot says that in the radio show
We are trying to show people how they can interpret the numbers that are thrown at them.
He advises people to ask simple questions, such as: Is that a big number? In the interview by Harford, Dilnot claims that the worst social statistic of all time was that the number of children killed in the United States has doubled every year since 1953.
One simple trick is to try to humanize statistics, Dilnot claims:
Faced with a question such as: how many petrol (gasoline in the US) stations are there in the UK?, ask yourself how many petrol stations there are in your town, and how many people. It’s the first step towards grasping a sensible answer to the bigger question.
Dilnot has written that just about the only question that can’t be partially answered with reference to personal experience is: how many penguins are there in Antarctica? due to the difficulties of a credible penguin census.
Questions
- What is wrong with the claim that the number of children killed in the United States has doubled every year since 1953?
- What is your estimate of how many penguins there are in Antarctica? What bounds do you wish to put around your estimate?
Further reading
- More or Less can be heard on Mondays on BBC Radio 4 at 16:30 BST and is presented by Tim Harford.
- More or Less is a permanent part of the schedule with two series annually, one in the summer, one in winter.
- Here is a link to the most recent version.
- Since January 2005, it has been produced in association with the Open University, who provide links to related webpages, such as: Statistics and the media and Guide to statistics.
- The Tiger That Isn’t, Andrew Dilnot's recent book covering similar topics to the radio show.
- Plus Magazine offer a review of this book.
- The Undercover Economist, a recent book by the new presenter, Tim Harford.
Submitted by John Gavin.
Name-Letter-Effect
An article in Psychological Science, Volume 18 Issue 12 Page 1106-1112, December 2007 by Nelson and Simmons has received much attention in the lay press, including, Sports Illustrated, Newsweek and USA Today. From the abstract of the article: "we found that people like their names enough to unconsciously pursue consciously avoided outcomes that resemble their names." In other words, as USA Today put it in its headline, "My name made me do it." Put another way, instead of astrology with its alignment of the stars at birth causing your success or failure, it is the name given to you that predicts behavior.
The article discusses five studies. The "it" in the first study refers to Major League Baseball players who have an initial "K"-the symbol for recording strikeouts--strike out more often, 18.8%, than players with other initials, 17.2%. This study looked at 6397 players who had at least 100 at bats. A hypothesis test was performed and the authors state that "t(6395) = 3.08," yielding a p-value of ".002." However, using the same database, a Blogger found otherwise; in particular, for 1960s to 2000s: Ks 14.5%, non-Ks 14.2%. This blogger concludes with, "So the big question remains: why did the authors get such a high strikeout rate difference?"
Here is why: Nelson and Simmons did not do the customary hypothesis test of difference in proportions but instead did a hypothesis test of the difference in means. That is, a batter's strikeout to at bat ratio was not weighted by the number of at bats.
The "it" in the second study refers to MBA academic performance at an unnamed institution. Looking at about 15,000 students, "As predicted, students whose names begin with a C or D earned lower GPAs than students whose names begin with A or B, F(4, 14348) = 4.55" yielding a p-value of ".001." The effect size is teeny and somehow, those whose initials are E through Z actually have the highest average GPAs.
Discussion
1. Baseball is full of slang. Two common terms for striking out are "fanning" and "whiffing." Obtain the data set and do a test for F or W to see what p-value ensues.
2. The figure below is Fig. 1 in the original paper where the GPAs of A, B, C, D, and Other are displayed. Why is the graph misleading?
http://www.dartmouth.edu/~chance/forwiki/Figure1.jpg Fig. 1. Results of Study 2: grade point average
as a function of the student's initial. Error bars in...3. The "it" in a third study looks at 492,458 lawyers at 170 law schools. The dependent variable is law-school quality which varies from Tier 1 (best), Tier 2, Tier 3, Tier 4 (worst). The independent variable is "the proportion of lawyers with initials A and B (relative to lawyers with initials C and D)." The regression result was a slope of -.17 yielding a p-value of .036. The authors conclude, "It seems that people with names like Adlai and Bill tend to go to better law schools that do those with names like Chester and Dwight." Comment on the qualitative nature of the dependent variable and how regression might be affected. Comment on Bill.
4. The Newsweek writer notes that "the GPA gap is tiny-3.34 versus 3.36." She then claims, "But there is a saying in science that if you discover a way to levitate objects with your thoughts by one millimeter, you don't focus on the millimeter-the size of the effect-but on the fact that something happened at all." Defend and criticize her statement.
Submitted by Paul Alper
{kind=link}