Chance News (September-October 2005)
Quotation
First get your facts; then you can distort them at your leisure.
Mark Twain
Do car seats really work?
Freakonomics: the seat-belt solution
New York Times, 10 July 2005,
Steven J. Dubner and Steven D. Levitt
Dubner and Levitt are the authors of Freakonomics: A Rogue Economist Explains the Hidden Side of Everything (HarperCollins, 2005), which raises a host of provocative questions, including "Why do drug dealers still live with their mothers?" and "What do schoolteachers and sumo wrestlers have in common?"
In the present article, Dubner and Levitt challenge the conventional wisdom on car seats. Their take-no-prisoners style is evident in the following quote: "They [car seats] certainly have the hallmarks of an effective piece of safety equipment: big and bulky, federally regulated, hard to install and expensive. (You can easily spend $200 on a car seat).” Indeed, regarding the third point, the National Highway Traffic Safety Administration (NHTSA) estimates that 80 percent of car seats are not installed correctly.
What then are the benefits? Here the authors cite another NHTSA statistic: “[Car seats] are 54 percent effective in reducing deaths for children ages 1 to 4 in passenger cars.” It turns out, however, that this compares riding in a car seat to riding with no restraint. Surely the relevant comparison, as suggested in the title of this article, is to riding with seat belts.
The authors concede that for children up to two years old, seat belts are not an option, so car seats logically offer some protection. But for children of ages 2 and older, federal Fatality Analysis Reporting System (FARS) data shows no decrease in overall death rate for children riding in cars seats compared with seat belts. Moreover, this conclusion does not change after controlling for obvious confounding variables such as vehicle size or number of vehicles involved in the accident.
But perhaps the potential benefit of car seats is being masked by the installation woes noted earlier. To check this, the article reports that Dubner and Levitt had an independent lab conduct crash tests, using both 3-year-old and 6-year-old dummies, to compare car seats to lap-and-shoulder seat belts. In 30 mile per hour crashes, the impact figures for 3-year-olds were “nominally higher” with seat belts; for 6-year-olds the figures were “virtually identical.” In addition, both restraint systems performed well enough against federal standards that no injuries would be expected.
Mr. Bubble comes back?
Be Warned: Mr. Bubble's Worried Again
The New York Times, August 21, 2005
David LeonhardtIrrational Exuberance: Second Edition
Princeton University Press, 2005
Robert J. ShillerWe read in the New York Times article:
In December 1996 Shiller, while having lunch with Federal Reserve Chairman Alan Greenspan, asked Greenspan: "When was the last time that somebody in his job had warned the public that the stock market had become a bubble?"
The next day, while driving his son to school, Shiller heard on the radio that stocks were plunging because Greenspan had asked in a speech whether "irrational exuberance" was infecting the markets. Shiller told his wife, "I may have just started a worldwide stock-market crash." She accused him of delusions of grandeurWell, the fall did not start immediately but Shiller's book which he titled “Irrational Exuberance” came out in April 2000, allowing the publisher to say: "the market crash predicted in this book started one month after it was published." Needless to say, Shiller's book became a best seller.
Shiller's book explains how irrational behavior leads to "speculative bubbles” defined as a situation in which temporarily high prices are sustained largely by investor's enthusiasm, rather than by consistent estimation of real value.
Shiller is one of the leaders in the new "Behavioral Finance" movement, which assumes that stock prices are influenced by irrational behavior of stock buyers, which, in many cases, can be explained in terms of modern psychology theory such as Kanaman and Tversky's results on irrational behavior. Shiller gives other types of information that effects stock prices. summarized by Jennifer Conrad's in her review in the Journal of Financial Research, April 1, 2001.
Part 1 of the book discusses the factors that might have contributed to, or amplified the size of, the bubble. These factors include changes in the institutional landscape (the rise in the use of mutual funds, the advent of day trading, the movement toward defined contribution pension plans), economic trends (the Internet), and broader societal factors (the collapse of communism, etc.) The discussion of "amplifying" factors in this section is essentially an argument about how a feedback loop may occur.
Part 2 discusses cultural factors that also could have contributed to the bubble (such as the news media and a shared error problem) and the propensity for "new age" thinking in the United States and elsewhere in the world. The author provides some historical examples of this last effect.
Part 3 discusses the possibility that psychological factors may influence the market.
Part 4 discusses the attempt by other authors to "rationalize" the stock market. This includes a discussion of the efficient market hypothesis, and the idea that there has been a paradigm shift, that is, that investors have learned that equities are not as risky as they previously appeared and have consequently bid up their prices.
In contrast to the behavioral finance, standard economic finance theory assumes that prices are determined by the rational behavior of stock experts analyzing the value of companies. The stock market is assumed to be "efficient," meaning that short-run changes in stock prices cannot be predicted. This is often interpreted to mean that stock market prices resemble a random walk.
The most well known proponent of this theory is Burton Malkiel whose book "A random walk down wall street" is in its 8th edition. Malkiel one suggested that a monkey throwing darts could do as well as the most sophisticated stock advisors. In his book Malkiel provides evidence that Mutual Funds do not do any better than standard indices such as the Dow. He does recognize that that irrational bubbles do occur and gives a history of economic bubbles starting with the famous 1593 Holland tulip-bulb craze.
At this point we recommend that you read the review of the first edition of Shiller’s book that Charles Grinstead wrote for Chance News 10.03. You will note that his only discussion question was: What do you think this reviewer did with his stocks after writing this review? The answer is: Charles took all his money out of stocks when the Dow was near its highest point before the crash.
Much of what Shiller writes about is best shown by the elegant graphics that he provides. The following graphic shows that the rise and fall of the stock market between 1990 and 2000 qualifies as a speculative bubble.
Real (inflation-corrected) S&P Composite Stock Price Index, monthly, January 1871 through January 2005 (upper curve), and real S&P Composite earnings (lower curve) January 1871 to September 2004.
In the preface of his second edition Shiller writes:
A number of people who read the book (first edition) have told me they think this book addressed a much broader subject. They are right: This book is really about the behavior of all speculative markets, about human vulnerability to error, and about the instabilities of the capitalist system.
If you review the factors that Shiller believes influences stock prices, you will see that most of them could apply equally well to housing prices. In his second edition Shiller suggests that the current housing prices constitute a speculative bubble that could in the not to distant future burst. To support this. Shiller looks at housing prices back to 1890 and from his data obtained the following graphic:
Heavy solid line: real (inflation-corrected) home price index, 1890 = 100, for the United Sates; thin line: real building cost index, 1979 = 100; lowest line: long term interest rate.
A home price index acts like a stock index in that it starts with the average of a group of houses whose values are known and determines the average value of this house at later times. Of course this is not always possible and other methods must be used to develop a home price index. But Shiller, with help by his students, was able to follow the values of a sample of houses over an extended period.
The most striking thing we notice is the sharp increase in house prices since the 1990's. There was a 52% increase in housing prices between 1997 and 2004. Only one other similar increase occurred and this was after World War II, which was probably caused by the fact that the GI Bill guaranteed loans for purchasing or building a home, or for repairs or improvements to existing homes. While it is a common belief that the price of a house can only go up, we see, taking into account inflation, there was only one period of time (after World War I) when prices have gone down and two periods when they have gone up. The rest of the time prices have been essentially flat.
Shiller also notes from his graphic that the "rocket taking off" of recent housing prices cannot be explained by increased building costs, increased population, or interest rates.
Shiller also notes that evidence for a bubble does not occur in all cities. To show this, he looked at home prices in a sample of 6 major cities and found the following results:
One has to admire Shilling’s desire and ability to get his own data and the imaginative way that he does that. Also before guessing what makes people buy stocks and houses at particular times he has carried out surveys over many years to get peoples opinions on buying and selling stocks and houses.
Of course Shiller is not the only one to use graphics and our last two graphics are from other peoples analysis of the housing market.
The first is a graphic that occurred in the article "Real Estate vulnerability Index" by Sara Clemenceon Forbes.com, June 3, 2005.
Economy.com calculated the affordability of real estate in major metropolitan areas, taking into account home sale prices, incomes and interest rates. The left side of the graph shows what percent of the median home a family earning the median income can buy. A higher number means housing is more affordable; a lower number means the average home is more out of reach.
At the "Real Estate vulnerability Index"you can see these cities individually. You will see that San Francisco, New York, and Los Angeles are currently at about 50, meaning that the average home would typically be out of the range of people in these cities. On the other hand Dallas, Atlanta and Houston are currently at about 200 making is easy for people in these cities to buy an average priced home. These seem consistent with Shillings house values except for Boston, which is at about 100, which seem inconsistent with the very high increase in the price of a house in Boston home found by Shilling.
Recall that Shiller's definition of a speculative bubble was a situation in which temporarily high prices are sustained largely by investor's enthusiasm, rather than by consistent estimation of real value.
In the case of stocks the real value can be estimated from current and future profits of the company. But what is it in the case of a house? One suggestion is that value of a house can be estimated by how much it would rent for. This suggests creating a price rental index. This can be done by using the price index of the Office of Federal Housing Enterprise Oversight (OFHEO) and the rental index developed by the Bureau of Labor as part of the consumer prince indexes. If these indexes are normalized to have value 1 and the ratio of the normalized indices are increasing faster than rental prices, this would suggest that it might be better to rent than to buy a house. The second gtraphic shows this price rent index.
We see from this graphic that prices are increasing much faster than rental's suggesting that renting is a better strategy than buying at this time. Note that there was a 1980 bubble in the LA, which took quite a long time to recover from.
Of course, if you are like my daughter Mary who is renting and wants to buy a house, what advice would you give from all this? Here is how Shiller responded when asked what should we do in an [interview] with Monday Magazine:
Q. So what should we do?
A. Most people want to live in their homes, so they should stay. But people can make decisions to reduce their home-price exposure. One possibility is to not be as ambitious about the size of your house. If you think that you'll move again in five years, then wait to buy your dream house.
Q. What about homeowners who are sitting on big paper profits -- should they cash out?
A. I wouldn't advise someone to sell, because their family situation is probably the dominant consideration. But if someone is at the margin, the question is timing. That's the problem with bubbles: Nobody knows when they will end.
The first answer is a little confusing but it sound like Mary should continue to rent for a few more years.
Submitted by Laurie Snell
Just how reliable are scientific papers?
Scientific accuracy ...and statistics, The Economist, 3 September 2005.
Why Most Published Research Findings Are False (pdf version), John P. A. IoannidisJohn Ioannidis, an epidemiologist, claims that 50% of scientific papers eventually turn out to be wrong.
While it is known that science is a Darwinian process, proceeding as much by refutation as by publication, no one has tried to quantify this issue until recently. The author sets out to understand how frequently highly cited studies are contradicted.
"There is increasing concern that, in modern research, false findings may be the majority or even the vast majority of published research claims," says Ioannidis in a related analysis, Most published research findings may be false, which appears in PLoS Medicine an open access, freely available international medical journal. (The Public Library of Science (PLoS), which publishes The PLoS Medicine is a non-profit organization of scientists and physicians committed to making the world's scientific and medical literature a freely available public resource.)
Ioannidis examined 49 articles which were cited at least 1,000 times in widely read medical journals between 1990 and 2003. But 14, about a third, were later refuted, such as hormone replacement therapy safety (it was, then it wasn't), vitamin E increasing coronary health (it did, then it didn't) and the effectiveness of stents in balloon angioplasty for coronary-artery disease (they are, but not as much as first claimed).
One source of error is unsophisticated reliance on "statistical significance," since twenty randomly chosen hypothesis are likely to result in one or more statistically significant results. In fields like genetics where thousands of possible hypothesis, genes that contribute to a particular disease, are examined, many (false) positive results will routinely occur purely by chance.
Other factors contribute to false results. One driving factor is sample size. "The smaller the studies conducted in a scientific field, the less likely the research findings are to be true," says Ioannidis. And another factor is effect size, such as drugs that work only on a small number of patients. Research findings are more likely to be true in scientific fields with large effects, such as the impact of smoking on cancer, than in scientific fields where postulated effects are small, such as genetic risk factors for diseases where many different genes are involved in causation. If the effect sizes are very small in a particular field, says Ioannidis, it is "likely to be plagued by almost ubiquitous false positive claims."
The author goes on to define a mathematical model to quantify sources of error. He concludes that a large, well-designed study with little researcher bias has only an 85% chance of being right. A small sample, poorly performing drug with researcher bias has only a 17% chance of reaching the right conclusions. And over half of all published research is probably wrong.
The author states his overall conclusions as follows:
- Contradiction and initially stronger effects are not unusual in highly cited research of clinical interventions and their outcomes. The extent to which high citations may provoke contradictions and vice versa needs more study. Controversies are most common with highly cited nonrandomized studies, but even the most highly cited randomized trials may be challenged and refuted over time, especially small ones.
In their related editorial, the PLoS Medicine editors discuss the implications of Ioannidis' analysis. They agree with him in some respects. They write, "publication of preliminary findings, negative studies, confirmations, and refutations is an essential part of getting closer to the truth." And the editors "encourage authors to discuss biases, study limitations, and potential confounding factors. We acknowledge that most studies published should be viewed as hypothesis-generating, rather than conclusive."
The original paper Contradicted and Initially Stronger Effects in Highly Cited Clinical Research, appeared in the Journal of the American Medical Association in July 2005. and is available on line for subscribers. The abstract is available on-line.
A related Guardian (September 8, 2005) article is Don't dumb me down. It states:
- Statistics are what causes the most fear for reporters, and so they are usually just edited out, with interesting consequences. Because science isn't about something being true or not true: that's a humanities graduate parody. It's about the error bar, statistical significance, it's about how reliable and valid the experiment was, it's about coming to a verdict, about a hypothesis, on the back of lots of bits of evidence.
In fact, the Guardian has a web page with weekly articles devoted to bad science. You are invited to make submissions. "If you are a purveyor of bad science, be afraid. If you are on the side, of light and good, be vigilant: and for the love of Karl Popper, email me every last instance you find of this evil. Only by working joyously together can we free this beautiful, complex world from such a vile scourge."
Discussion
Dr Ioannidis's study focuses on medical research only. Would the same conclusions be applicable to other sciences such as physics or is there an inherent bias in his research?
The Economist article finishes by asking, "Is there a less than even chance that Dr. Ioannidis's paper is itself wrong?"
Submitted by John Gavin.
Paulos on errors in medical studies
Why medical studies are often wrong; John Allen Paulos explains how bad math haunts heath research
Who's Counting, ABCNews.com, 7 August 2005
In this installment of his online column, Paulos considers the JAMA report about contradictions in health research (Ioannidis, J.P.A. Contradicted and initially stronger effects in highly cited clinical research. JAMA, July14, 2005; 294:218-228 ). This research is well described above.
In the present article, Paulos cites a number of reasons for the problems. A single study is rarely definitive, but headlines and soundbites usually don't wait for scientific consensus to develop. People fail to appreciate differences in quality of research. Experiments are stronger than observational studies; in particular, surveys that depend on patients' self-reporting of lifestyle habits can obviously be unreliable. These ideas echo points made by the medical journals themselves in response to news reports (see, for example, see this Associated Press report).
Paulos also describes some conflicting psychological responses to medical news. People can be overly eager to believe that a new treatment will work. On the other side of the coin, in what he calls the "tyranny of the anecdote," people also overreact to stories of negative side-effects, even though such incidents may be isolated.
DISCUSSION QUESTION:
On the last point, Paulos writes:
A distinction from statistics is marginally relevant. We're said to commit a Type I error when we reject a truth and a Type II error when we accept a falsehood. In listening to news reports people often have an inclination to suspend their initial disbelief in order to be cheered and thereby risk making a Type II error. In evaluating medical claims, however, researchers generally have an opposite inclination to suspend their initial belief in order not to be beguiled and thereby risk making a Type I error.
Do you understand the distinction being drawn? To what hypotheses does this discussion refer?
Poor people receive worst public services
In the UK, it seems that the poorer you are the less likely you are to have access to public services, such as health care. This counter intuitive result is known as the "inverse care law" - those in greatest need have the worst services. A new set of reports from the Joseph Rowntree Foundation (JRF) sets out to graphically illustrate the nature and extent of geographical and social inequality in the UK at the beginning of the twenty-first century.
This study addresses inequalities using data from the 2001 Census, such as the geographical relationship between poverty, affluence and area. Appropriate Census data were extracted from the Census database and their distribution explored using maps, graphs and charts.
For example, 4.5 million people in the UK reported that they had both poor health and a limiting long-term illness in 2001. 5.9 million people said they provide care to family and friends on an informal basis. The amount of this informal care is provided in direct proportion to the rate of poor health in areas across the UK. The authors use a carefully constructed graph, based on census data, to illustrate the strong relationship between the two social variables.
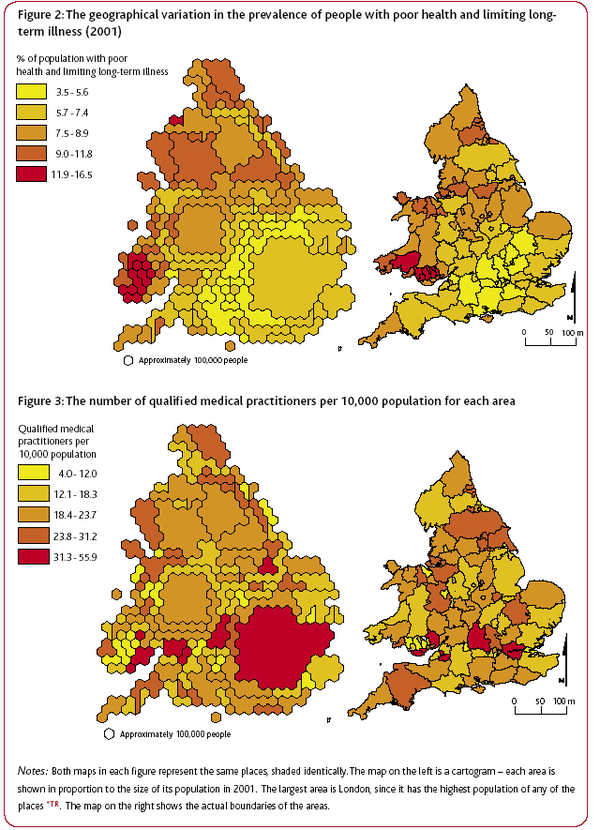 Geographical distribution of poor health and doctors in the UK. Source: JRF report: Life in Britain
Geographical distribution of poor health and doctors in the UK. Source: JRF report: Life in BritainAnother report, Life in Britain, provided a geographical graph of the ‘inverse care law’. The authors use geographic data from the 2001 cencus to highlight that higher numbers of practising, qualified medical practitioners tend to live and work in areas where the rates of illness are lower.
In both figures, the cartograms on the left shows each area in proportion to its population in 2001. The largest area is London, as it has the highest population density. The right hand map shows the actual boundaries of the areas.
The authors comment on the graph that "perversely, people living in the poorest neighbourhoods with the greatest needs are often the least likely to have access to the services and support that would help them improve their lives." Given these results, the authors are not surprisingly very negative on their views of social equality in the UK today. Prof. Dorling said "it is acutely disappointing to discover that so many opportunities and resources still depend on where people live." And Dr Ben Wheeler, also from the University of Sheffield, said that "the census data shows quite clearly that although living standards have increased in 60 years, the rich and poor in Britain continue to live in two different worlds."
These graphs demonstrates the power of the Census to provide easily interpreted data that consider the entire population and make obvious the continued unequal distribution of resources and prospects in the UK today.
The authors advocate the use of simple quantitative methods throughout their work, the most complex being correlation coefficients. Typically, they use pairs of variables, derived from the Census data, are compared across the geographical areas, with most pairs representing one measure of need and one measure of availability. The objective is demonstrates associations rather than proving causes.
A related ‘inverse education law’ also appears to exist in the case of education. Areas which have the highest proportions of young people with no qualifications tend to have the fewest teachers available.
Further reading
Guardian Unlimited, Matt Weaver, September 1, 2005.
JRF report: poverty, affluence and area (pdf file), Dr Ben Wheeler and Professor Danny Dorling from the University of Sheffield, Dr Mary Shaw from the University of Bristol and Dr Richard Mitchell from the University of Edinburgh.
JRF report: Life in Britain A pack summarising the results of the analysis of the UK 2001 Census data was published by The Policy Press. It is intended for use by students, their teachers and a wide range of practitioners and policy makers, and consists of 10 short reports, a summary, a technical report and 5 A2 posters.Some parts of some Joseph Rowntree Foundation reports are available on-line and are well worth reading for background information on social policy and poverty. For example, Thomas Clarkson won a prize in 1785, while he was a student at Cambridge, for An essay on the impolicy of the African slave trade. His essay includes an analysis of the very high rates of mortality (20%) among seamen on board eighty-eight slave ships that returned to Liverpool from their respective voyages in September 1787. This analysis was intended to counter the then prevalent pro-slavery argument that slave trade provided a nusery for British seamen. He includes some chilling graphics on life for slaves on board as well. This essay provoked him to pursue the goal of the abolition of slavery. This link also provides a harrowing extract from his book, History of the abolition of the African slave trade, which was first published in 1817, in which he gives more details of conditions of the lives of slaves.
The same link also contains the more statistically orientated opening chapter from Richard Titmuss' 1943 book Birth, poverty and wealth. Titmuss used statistical data from many sources to show that premature death was most likely in the lowest occupational groups, least likely in the highest. Titmuss knew that the evidence did not allow him to be dogmatic about the relative importance of heredity and environment but he was still forceful in his conclusions
'The fact that for every eleven infants of the economically favoured groups who die from preventable causes, 90 children of the poor die from similar causes summarises, as a matter of life or death, the power of environment and economics.’
Its publication was greeted with the newspaper headline Poor folks' babies stand less chance.
Discussion
Do you think that a lack of doctors lead to areas with generally poor health, or are areas with generally poor health unattractive places for doctors for they live, causing them to relocate elsewhere?
Submitted by John Gavin.
Statistics could have spotted mass murderer
NewScientist.com news service, John Pickrell, 06 September 2005.
Plotting death Emma Young, New Scientist, 09 February 2001.In 2000 Harold Shipman, a UK family doctor, was convicted of murdering 15 patients. Statistical quality-control methods might have allowed authorities to catch Shipman much sooner, according to a new study. David Spiegelhalter of the UK Medical Research Council's Biostatistics Unit, Cambridge, UK, has applied an industrial quality-control technique to data on the death of Shipman's patients to see if his heinous crimes could have been detected any earlier. "The method was first used in 1943 to ensure consistent quality in explosive shells and other wartime munitions production lines", says Spiegelhalter. The same statistics are used today in a wide range of industries, but have never before been applied to healthcare performance.
These methods on their own are not enough but cross-referencing other factors such as time of death or location might have set alarm bells ringing – many of Shipman's victims were murdered at around 3pm, during his afternoon rounds, and anomalous numbers died while in Shipman’s presence. "Maths has many crime-fighting applications," comments applied mathematician Chris Budd at the University of Bath, UK. "Statistics can be a useful approach for detecting anomalies in many contexts," he says.
The control-chart graphical method was developed by US physicist Walter Shewhart for use in the manufacturing industry. Scores are not ranked into a league table. Instead, the number of adverse outcomes is plotted against the total number of cases on a graph. A line is drawn through the mean, and all scores within three standard deviations (in practice, most of the scores) are considered to be down to inherent variation in the system. Any scores outside the 'control limits' suggest a special cause. Tom Marshall, of the University of Birmingham, told New Scientist.
This tells you where the real problems in a system are. In a league table, someone has to be at the top and someone has to be at the bottom, but that doesn't necessarily mean any kind of intervention should be taken.
However, Spiegelhalter believes his method is more powerful as it allows data from multiple years to be assessed.
A remarkable story about the German Lotto
A Miracle in the German Lotto
Strange But True, Richmond.com
April 26, 2005
Bill Sones and Rich Sones
(reprinted with permission of Bill and Rich Sones)
Q. In the German Lotto on June 21, 1995, the numbers 15-25-27-30-42-48 were drawn out of 49. Bizarrely, it was later discovered that these same 6 had been drawn on Dec. 20, 1986, something that hadn't happened before in the 3,016 drawings of the Lotto. With nearly 14 million combos possible, how incredible was this really? Was someone rigging the picks?
A. Pardon the daunting math, but to figure the likelihood of getting a match in 3,016 drawings, first you need to figure the likelihood of getting NO matches, says Henk Tijms in his new book "Understanding Probability." Start by multiplying 13,983,816 x (13,983,816 - 1) x (13,983,816 -2)... x (13,983,816 - 3,015). There are 3,016 factors here.
Then divide by 13,983,816 to the 3016 power! Once your overworked computer cools off, you'll see an answer of 0.7224. But that's the likelihood of no matches; instead subtract 1 - 0.7224 to find the likelihood of at least one match, which equals 0.2776. This means there was a better than 1 in 4 chance that this would happen in 3,016 drawings!
What fools people is that the chance of matching a PARTICULAR 6-number-sequence is vanishingly small, but not the chance of matching SOME 6-number-sequence along the way. Says Tijms: This is basically another version of the classic birthday paradox, where all it takes is 23 people in a room for there to be a 50-50 chance of at least two of them having the same birthday. "In the lottery situation, it's analogous to there being 3,016 people in the room and 13,983,816 possible birthdays." So no rigging necessary, but just someone's incredible recordkeeping to track thousands of picks and spot the repeat.
Discussion
The article says that the math is "daunting." Is it really so daunting? Where did the authors get the calculation that divides 13,983,816 x (13,983,816 - 1) x (13,983,816 -2)... x (13,983,816 - 3,015) by 13,983,816 to the 3016 power? Is there a better way to arrange the calculation so that your computer won't be so overworked?
Self Experimentation
Does the Truth Lie Within? The New York Times, September 11, 2005 Stephen J. Dubner and Steven D. Levitt
Another article in the New York Times by the authors of Freakonomics discusses self experimentation. The authors highlight the work of Seth Roberts:
Seth Roberts is a 52-year-old psychology professor at the University of California at Berkeley. If you knew Roberts 25 years ago, you might remember him as a man with problems. He had acne, and most days he woke up too early, which left him exhausted. He wasn't depressed, but he wasn't always in the best of moods. Most troubling to Roberts, he was overweight: at 5-foot-11, he weighed 200 pounds.
When you encounter Seth Roberts today, he is a clear-skinned, well-rested, entirely affable man who weighs about 160 pounds and looks 10 years younger than his age. How did this happen?
The authors go on to say that all of Seth Roberts ills were cured by self experimentation. He tried various interventions and evaluated the results.
It took him more than 10 years of experimenting, but he found that his morning insomnia could be cured if, on the previous day, he got lots of morning light, skipped breakfast and spent at least eight hours standing.
Losing weight depended on a theory of weight regulation known as the set-point theory which says that your weight is determined by what you needed to survive during stone age times because
when food is scarcer, you become less hungry; and you get hungrier when there's a lot of food around.
This encouraged us to store food when it was plentiful as fat so as to help us survive when food becomes scarce. It worked well long ago, but today food is plentiful all year round, so the signal to stop storing fat never gets turned off. Seth Roberts experimented with flavors that might trick the set-point system into thinking that food was actually scarce. A bland, unflavorful diet might work, he theorized, but no one wants to be stuck eating like that. He found that a few tablespoons of unflavored oil worked as did several ounces of sugar water.
The results were astounding. Roberts lost 40 pounds and never gained it back. He could eat pretty much whenever and whatever he wanted, but he was far less hungry than he had ever been. Friends and colleagues tried his diet, usually with similar results.
These self experiments are a special case of the "N of 1 trials." A good example of this type of trial appears in the British Medical Journal: Jeffrey Mahon, Adreas Laupacis, Allan Donner, Thomas Wood. Randomised study of n of 1 trials versus standard practice. BMJ 1996; 312: 1069-1074 (27 April). Full free text The N of 1 trial is simply a crossover trial with a single patient.
Numerous references and additional details are at the Freakonomics website
There are several amusing examples of self experimentation at this website, but not mentioned is one of my personal favorites, the 1994 Ig Nobel prize winner in Entomology:
Robert A. Lopez of Westport, NY, valiant veterinarian and friend of all creatures great and small, for his series of experiments in obtaining ear mites from cats, inserting them into his own ear, and carefully observing and analyzing the results. [Published as "Of Mites and Man," The Journal of the American Veterinary Medical Association, vol. 203, no. 5, Sept. 1, 1993, pp. 606-7.]
Discussion
One potential source of bias in self experimentation is the inability to adequately blind the patient. What other sources of bias are there in this type of study?
Most research requires the informed consent of the research subject. Is informed consent an issue in self experimentation?
Submitted by Steve Simon
Text Stats - squeezing the life out of poetry and prose
Amazon's Vital Statistics Show How Books Stack Up, Linton Weeks, Washington Post, August 30, 2005.
Amazon.com has a new capability. called Search Inside, which allows users to search through the entire text of a book online. This functionality produces some elementary statistics such as the number of letters, words and sentences. The Fun Stats section tells you how many words you are getting per dollar and per ounce with each book. So Leo Tolstoy's War & Peace offers 51,707 words per dollar, while Obliviously On He Sails: The Bush Administration in Rhyme by Calvin Trillin delivers only 1,106 words per dollar. When The Washington Post confronted Trillin with this evidence, he replied,
"I don't mind being compared to Tolstoy literarily, but when it comes to Fun Stats it's a little humiliating."
Search Inside also tries to quantify the readability and complexity of a book and to graphically display the most common words, called concordance, by setting the font size to be proportional to the number of times that word occurs in the book, a very simple yet surprisingly effective technique. (Incidently, the same graphical tool is used by flickr.com to display its most popular images, based on the tags that have been added to them, a new way to organise information that may eventually replace folders (click on the pdf download button and see Death to folders! on page 18).) A book's readability is quantified using the three statistics: the Fog, Flesch and Flesch-Kincaid indices and it also graphically ranks your chosen book's stats, relative to others books, but in a rather uninspiring manner. Complexity is quantified as the percentage of words with three or more syllables, the average number of syllables per word and words per sentence.
The Washington Post quantifies it favourite books:
Ulysses by James Joyce (9 on the Fog Index) is more complicated than William Faulkner's The Sound and the Fury (5.7 on the Fog Index). Yes, Charlotte Bronte provides more words per ounce (13,959) in Shirley than her sister Emily (10,444) in Wuthering Heights. And, yes, Ernest Hemingway used fewer complex words (5 percent) in his short stories than F. Scott Fitzgerald (9 percent).
But they are distinctly unimpressed by the cold, harse statistics:
But in its pure form, Text Stats is a triumph of trivialization. By squeezing all the life and loveliness out of poetry and prose, the computer succeeds in numbing with numbers. It's the total disassembling of truth, beauty and the mysterious meaning of words. Except for the Concordance feature, which arranges the 100 most used words in the book into a kind of refrigerator-magnet poetry game.
Discussion
Can you think of alternative ways to quantify readability and complexity?
What alternative graphics might be suitable to display the statistics?
Try searching for your favourite author's books to see if his/her stats are improving over time.
Submitted by John Gavin.
Amazon Uses Chance to Target Customers
I received this email from Amazon.com:
Amazon.com has new recommendations for you based on 17 items you purchased
or told us you own.
We recommend LaTeX Companion, The (2nd Edition) (Addison-Wesley Series on Tools and Techniques for Computer T)
List Price : $59.99
Price : $45.86
You Save : $14.13 (24%)
Because you purchased or rated: The LaTeX Graphics Companion: Illustrating Documents with TeX and Postscript(R) you are 9,290 times more likely to purchase this item than other customers.
We hope you like these recommendations and would love to hear your feedback
on our recommendations algorithm. Email us at cb-arr-lift@amazon.com.
Submitted by Bob Hayden.
Warned, but Worse Off
According to an article in the New York Times (August 22, 2005), people whose lung cancers are detected by CT scans have a five-year survival rate of 80 percent, whereas those whose cancers are detected by conventional means have a five-year survival rate of only 15 percent. Is this a good reason for someone at risk for this disease to get a CT scan?
The answer is that no one knows. It may be that CT scans don't actually result in people living any longer than they would otherwise, and the epidemiology is at this point not understood well enough.
There are two issues: First, CT scans are capable of detecting a cancer in an earlier stage (since they can detect smaller tumors), but it's not clear that earlier detection and treatment of these cancers actually adds anything to the lifespan. For example, if a tumor was detected at a stage when the patient would have survived for six years, regardless of treatment, but would only have been detected conventionally three years later, then the result would be that this patient would be included in the statistics of those that survived five years after detection by CT scan, but a similar patient whose cancer was detected conventionally would not be included in the five-year survival rate for those patients.
The second issue involves the fact that CT scans may detect a large number of small tumors that do not progress. We know that smokers are 15 times more likely to die from lung cancer than nonsmokers, yet in a Japanese study, CT scans detected tumors at similar rates in both smokers and nonsmokers. Evidently, most of the tumors found in the nonsmokers don't progress to become life-threatening.
The consequences may be serious. If CT scans don't really result in much prolongation of life, the result of using them may actually be a net negative for most patients, who might undergo unnecessary biopsies and other followup treatments.
Discussion
Often it is not enough to calculate only probabilities, for decisions must also be made, and these do not depend only on probabilities. In a medical context, patients need to know what their risk of having a disease is, given the results of the tests they have had; but if the risk is very low, the patient also needs to know what the consequences of followup treatment or diagnosis is likely to be. How do you think a patient should go about making such a decision, based on both these factors?
Further reading
An elementary discussion of the problem of making decisions under uncertainty may be found in J. S. Hammond, R. L. Keeney and H. Raiffa, Smart Choices.
Contributed by Bill Jefferys
Warned, but Worse Office
this is a test






